

By [Journalist Name]
Published: June 15, 2026
In the rapidly evolving landscape of artificial intelligence, the prevailing wisdom has long been that "bigger is better." For years, the industry has been dominated by a handful of "frontier" models—monolithic, multi-billion-dollar entities like OpenAI’s GPT series or Anthropic’s Claude. However, a significant shift is underway. OpenRouter, a leading aggregator of AI model APIs, has launched a new product called "Fusion" that suggests the future of intelligence may not lie in a single massive brain, but in a carefully orchestrated choir of smaller ones.
The launch of Fusion represents more than just a new tool for developers; it is a strategic bet on the efficiency of "compound models." By leveraging a panel of relatively inexpensive AI models and synthesizing their outputs through a sophisticated judge-and-synthesizer architecture, OpenRouter claims to match the performance of the world’s most expensive AI—Claude Fable 5—at approximately half the cost.
Main Facts: Architecture and the ‘Wisdom of the Crowd’
At its core, OpenRouter Fusion is an API built on the principle of ensemble modeling. Rather than relying on one high-parameter model to parse a complex query, Fusion distributes the task across a diverse array of "cheap" models in parallel.
The workflow is a three-stage process occurring entirely on the server side:
- Parallel Execution: When a prompt is received, Fusion fires it off to a panel of models simultaneously. In the default configuration, these models are equipped with real-time web search and bash execution tools, allowing them to gather external data and perform technical tasks independently.
- The Judicial Phase: Once the initial responses are generated, a "judge model" analyzes the outputs. Its role is to identify consensus points where models agree, highlight contradictions where they differ, and spot potential "blind spots" or hallucinations in individual responses.
- Synthesis: Finally, a "synthesizer"—by default, the highly capable Claude Opus 4.8—takes the raw responses and the judge’s analysis to craft a single, grounded, and comprehensive final answer.
This architecture aims to solve the "single-point-of-failure" problem inherent in solo models. Even the most advanced AI can suffer from "hallucinations" or logical lapses. By forcing multiple models to "show their work" and then cross-referencing those results, Fusion attempts to filter out errors before they reach the user.
Chronology: A Perfect Storm of Regulation and Innovation
The timing of OpenRouter’s launch was not merely a matter of technical readiness; it was a masterclass in market opportunism driven by geopolitical shifts.
The Release of Fable 5 (Early June 2026):
Anthropic released its highly anticipated Claude Fable 5 and Mythos 5 models to much fanfare. These models were hailed as the new benchmark for "frontier intelligence," particularly in long-horizon reasoning and complex coding. However, their high performance came with a high price tag and significant compute requirements.
The Export Control Directive (June 10, 2026):
Just days after the release, the U.S. government issued a surprise export control directive. Citing a disputed "jailbreak" finding that suggested Fable 5 could be used to bypass critical cybersecurity protocols, the government ordered Anthropic to suspend access to the models for all foreign nationals worldwide. This move effectively cut off a massive portion of the global developer community from the world’s most powerful AI overnight.

The OpenRouter Response (June 11-13, 2026):
Recognizing the immediate vacuum in the market, OpenRouter took to social media (X) to announce Fusion. Their pitch was direct: "Fable-level intelligence at half the price." By utilizing models that were not subject to the same restrictive export controls—including open-source models from international providers—OpenRouter offered a path forward for developers who had been sidelined by the U.S. directive.
Supporting Data: Benchmarking Fusion Against the Giants
To validate their claims, OpenRouter tested Fusion against the DRACO benchmark. Developed by Perplexity, DRACO is widely considered one of the most rigorous evaluations for AI, as it is constructed from real-world, "deep research" requests made by human users.
The Performance Gap
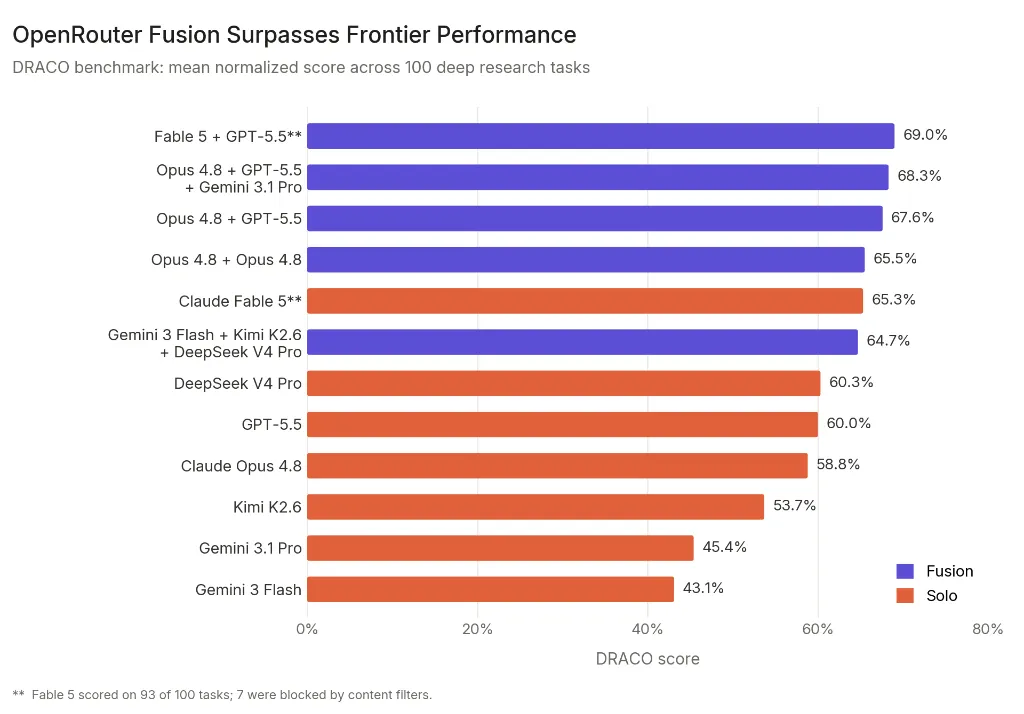
The results of the DRACO testing provided a compelling case for the compound model approach:
- Solo Claude Fable 5: Scored 65.3%. Notably, 7% of its tasks failed to run because the model’s internal safety filters blocked the requests, illustrating the friction often found in highly regulated frontier models.
- Fusion (High-End): When Fable 5 was paired with OpenAI’s GPT-5.5 and synthesized by Claude Opus 4.8, it topped the charts at 69%, demonstrating that even the best models benefit from an ensemble approach.
- Fusion (Cost-Effective): The "value" configuration—pairing Google’s Gemini 3 Flash with Chinese models Kimi K2.6 and DeepSeek V4 Pro, synthesized by Opus 4.8—hit 64.7%.
This "value" configuration is the centerpiece of OpenRouter’s strategy. At 64.7%, it sits within a fraction of a percentage point of solo Fable 5 (65.3%) while beating solo GPT-5.5 (60%) and solo Opus 4.8 (58.8%) by significant margins.
The Economics of Inference
The primary draw for enterprises is the cost-to-performance ratio. According to OpenRouter’s published cost charts, the Fusion "value" panel delivers its results at roughly 50% of the cost per million tokens compared to a solo Fable 5 call.
OpenRouter’s internal telemetry suggests that roughly 75% of the performance "lift" in Fusion comes from the synthesis step itself—the act of a high-level model reviewing the work of others. The remaining 25% is attributed to "model diversity," where different architectures (such as the reasoning-heavy DeepSeek vs. the retrieval-efficient Gemini) catch each other’s mistakes.
The "Contamination" Fix
During the benchmarking process, a technical hurdle emerged. Because the models in the Fusion panel have live web access, some models inadvertently surfaced the DRACO grading rubric during their search phase. OpenRouter addressed this "contamination risk" by adding a single configuration line to exclude the benchmark’s hosting domains from the search tools. The published 64.7% score reflects this "clean" run, ensuring the results are based on reasoning rather than "cheating."
Official Responses and Market Sentiment
The reaction from the AI community has been polarized, reflecting a broader debate about the transparency and reliability of compound systems.
The Proponents:
Andrew Trask, a prominent AI researcher, described Fusion as "a way bigger deal than it seems." Trask argued that this marks a turning point where "frontier labs will never again own the frontier alone." His view suggests that if software orchestration can bridge the gap between "good" and "great" models, the competitive advantage of having the largest training cluster begins to evaporate.
The Skeptics:
On the other hand, some developers have expressed caution. Critics pointed out that while Fusion excels at research and synthesis, it struggles with "tool-calling" and complex coding loops. On platforms like X, users noted that the latency of running multiple models in parallel—even if done asynchronously—can be a deterrent for real-time applications. Furthermore, some argued that because Fable 5 is currently unavailable to many, OpenRouter’s comparisons lack the transparency of a true head-to-head live test.
OpenRouter’s Stance:
OpenRouter has been transparent about the tool’s limitations. They explicitly state that Fusion is not a "wholesale swap" for a frontier model in every use case. For "long-horizon" work—tasks that require maintaining a massive context over thousands of steps—solo frontier models like Fable still hold the edge.
Implications: The End of the Frontier Monopoly?
The launch of Fusion signals three major shifts in the AI industry:
1. The Democratization of "Frontier" Intelligence
If the "Wisdom of the Crowd" can indeed match the "Genius of the Individual," then the barrier to entry for high-level AI applications has just dropped. Startups no longer need to wait for a single provider to lower their prices; they can build their own "frontier" by stitching together more affordable components. This shifts the value proposition from compute to orchestration.
2. Geopolitical Resilience in AI
The U.S. export controls on Anthropic demonstrated how fragile the global AI supply chain is when it relies on a few centralized, regulated entities. By incorporating models like DeepSeek (China) and Gemini (U.S.) into a single pipeline, Fusion provides a form of "regulatory arbitrage." If one model is banned or restricted, the system can be reconfigured with an alternative, making AI access more resilient to geopolitical tensions.
3. The Shift Toward Software-Defined Intelligence
For years, the "Scaling Laws" dictated that more data and more GPUs were the only path to better AI. Fusion suggests a new path: "Inference-time Scaling." By spending more compute at the moment of the request (running multiple models and a synthesizer) rather than just during training, developers can squeeze more intelligence out of existing architectures.
As we move into the latter half of 2026, the success of Fusion will likely inspire a wave of "compound-first" startups. The era of the monolithic AI giant is far from over, but for the first time, the "crowd" is starting to look like a formidable challenger. Whether Fusion remains a niche tool for researchers or becomes the new standard for enterprise API integration will depend on how quickly OpenRouter can solve the remaining hurdles of latency and tool-calling reliability. For now, however, the message is clear: the frontier is no longer a private club.
