

In the rapidly shifting landscape of artificial intelligence, the year 2026 has become defined by a pivot from conversational interfaces to autonomous action. The latest milestone in this evolution arrived late last week as DeepReinforce, a specialized AI research lab, announced the release of Ornith-1.0. This new family of open-source models is specifically engineered for "agentic" coding—a paradigm where AI does not merely suggest lines of code but actively navigates software repositories, executes tests, and debugs failures without human intervention.
The release includes four distinct model sizes, ranging from a compact 9-billion-parameter version to a massive 397-billion-parameter Mixture-of-Experts (MoE) flagship. Distributed under the MIT license with no regional restrictions, Ornith-1.0 represents a significant challenge to proprietary giants like Anthropic and OpenAI, signaling a new era for open-source dominance in the developer tools sector.
Main Facts: The Ornith-1.0 Architecture and Licensing
DeepReinforce’s Ornith-1.0 is not a general-purpose large language model (LLM). Instead, it is a specialized toolset designed for the "agentic" workflow. Unlike traditional coding assistants that act as advanced autocomplete engines, Ornith is built to function as an independent developer.
A Family of Four Sizes
The lab has released the models in four configurations to cater to different hardware capabilities and use cases:
- 9B Dense: A small, highly efficient model capable of running on high-end consumer hardware or edge devices. Despite its size, it punch above its weight in specific coding benchmarks.
- 31B Dense: A mid-range model designed for local workstations, balancing reasoning depth with inference speed.
- 35B Mixture-of-Experts (MoE): An architecture that activates only a fraction of its parameters for any given task, offering a middle ground for enterprise-level local deployments.
- 397B MoE Flagship: The "heavyweight" model designed for data centers. This version is built to handle the most complex, multi-step engineering tasks that typically require human senior developer oversight.
Open-Source Philosophy
In a move that distinguishes DeepReinforce from many of its competitors, the entire Ornith-1.0 family is released under the MIT License. This means there are no restrictions on commercial use, modification, or distribution, and critically, no regional "gating" that has recently plagued other high-profile AI releases. By hosting the weights on Hugging Face, DeepReinforce is positioning Ornith as the foundational infrastructure for the next generation of self-hosted coding agents.
Chronology: From CUDA-L1 to the Agentic Breakthrough
The release of Ornith-1.0 is the culmination of several years of focused research into how AI handles complex, non-linear tasks. DeepReinforce first gained notoriety in the developer community for CUDA-L1, a specialized optimization tool, and later for the IterX code-agent optimization loop.

IterX was a precursor to the philosophy found in Ornith. It focused on "iteration"—the idea that an AI’s first draft is rarely its best, and that true intelligence in coding comes from the ability to run code, see where it breaks, and fix it. Throughout 2025 and early 2026, DeepReinforce shifted its focus from building "harnesses" for existing models to building a model that could be the harness itself.
The "agentic" focus was born out of a realization that while models like GPT-4 and Claude 3.5 were excellent at writing functions, they struggled when placed in a 20-step workflow involving directory navigation, dependency management, and environmental debugging. Late in 2025, the lab began the training run for Ornith, utilizing a novel reinforcement learning (RL) approach that prioritized strategy over syntax.
Supporting Data: Benchmarking the Autonomous Engineer
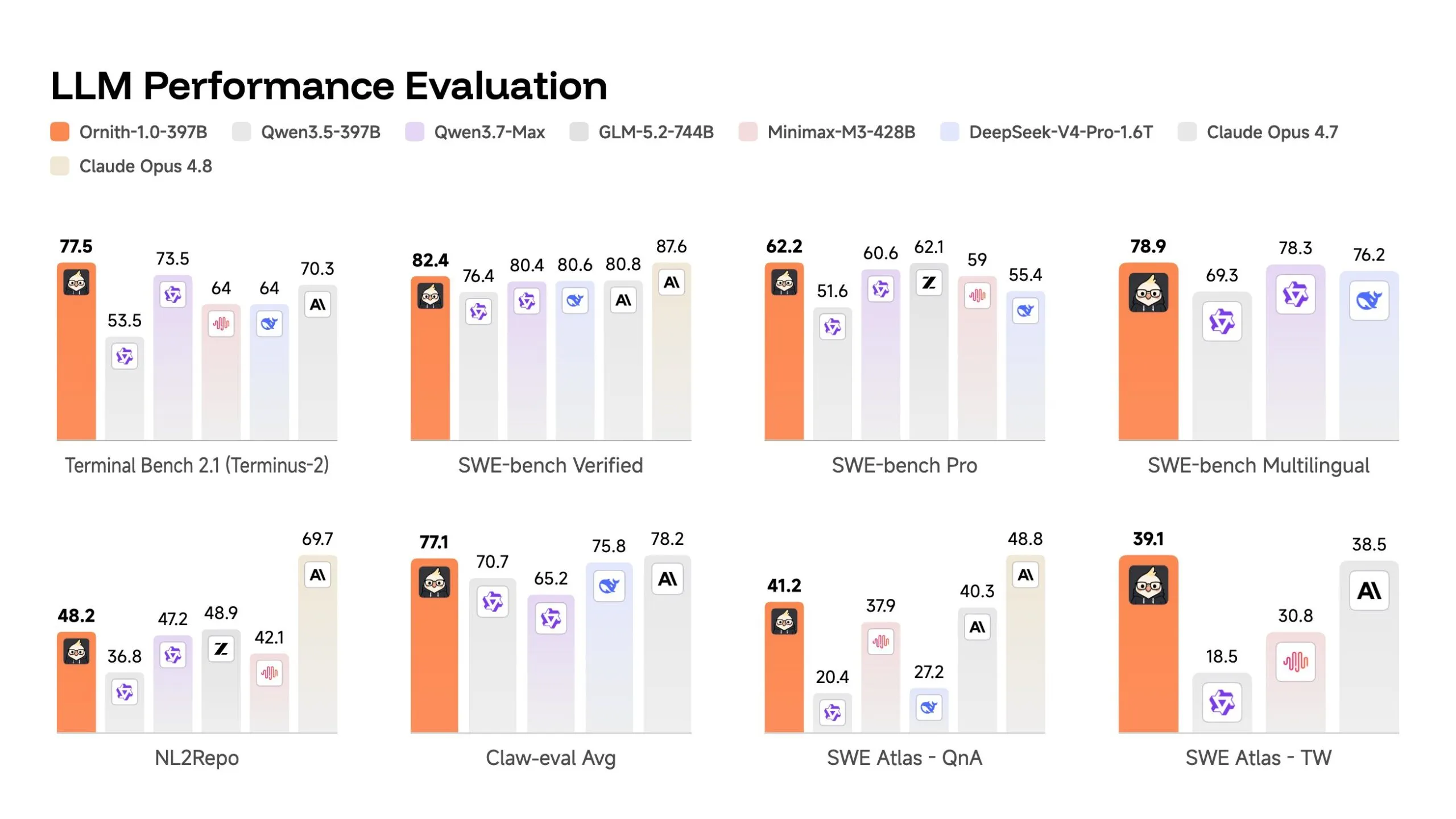
The performance of Ornith-1.0-397B has sent ripples through the industry, particularly for its performance on SWE-bench Verified. This benchmark tasks an AI with resolving real-world bugs pulled from GitHub repositories. The AI is given the issue description and the codebase but cannot see the hidden test suite used for grading.
Comparative Performance
According to the data released by DeepReinforce:
- Ornith-1.0-397B: Scored 82.4 on SWE-bench Verified.
- Claude Opus 4.7: Scored 80.8.
- DeepSeek-V4-Pro: Scored 80.6.
In Terminal Bench 2.1, which measures an AI’s ability to operate within a containerized terminal environment (handling tasks like async debugging and security patching), the Ornith flagship posted a score of 77.5, significantly outperforming Claude Opus 4.7’s 70.3.
Addressing the Contamination Crisis
Earlier in 2026, OpenAI and other researchers raised concerns that many models were "gaming" benchmarks by memorizing solutions present in their training data—a phenomenon known as data contamination. To address this, DeepReinforce also tested Ornith on SWE-bench Pro, a more rigorous version of the test using newer, less-leaked codebases.
- On SWE-bench Pro, the 397B model scored 62.2. While lower than the "Verified" score, it remains highly competitive and notably superior to DeepSeek’s latest offerings, suggesting that Ornith’s reasoning is genuinely generative rather than memorized.
The 9B "Small Giant"
Perhaps the most surprising data point is the performance of the smallest model. The 9B Dense model posted a 69.4 on SWE-bench Verified. To put this in perspective, this 9-billion parameter model outperformed the Gemma 4-31B (which scored 52) and nearly matched the Qwen 3.5-35B (which scored 70), despite being a fraction of their size. This suggests that DeepReinforce’s training efficiency for coding-specific tasks is currently world-class.
Official Responses: "Treating the Scaffold as a Learnable Object"
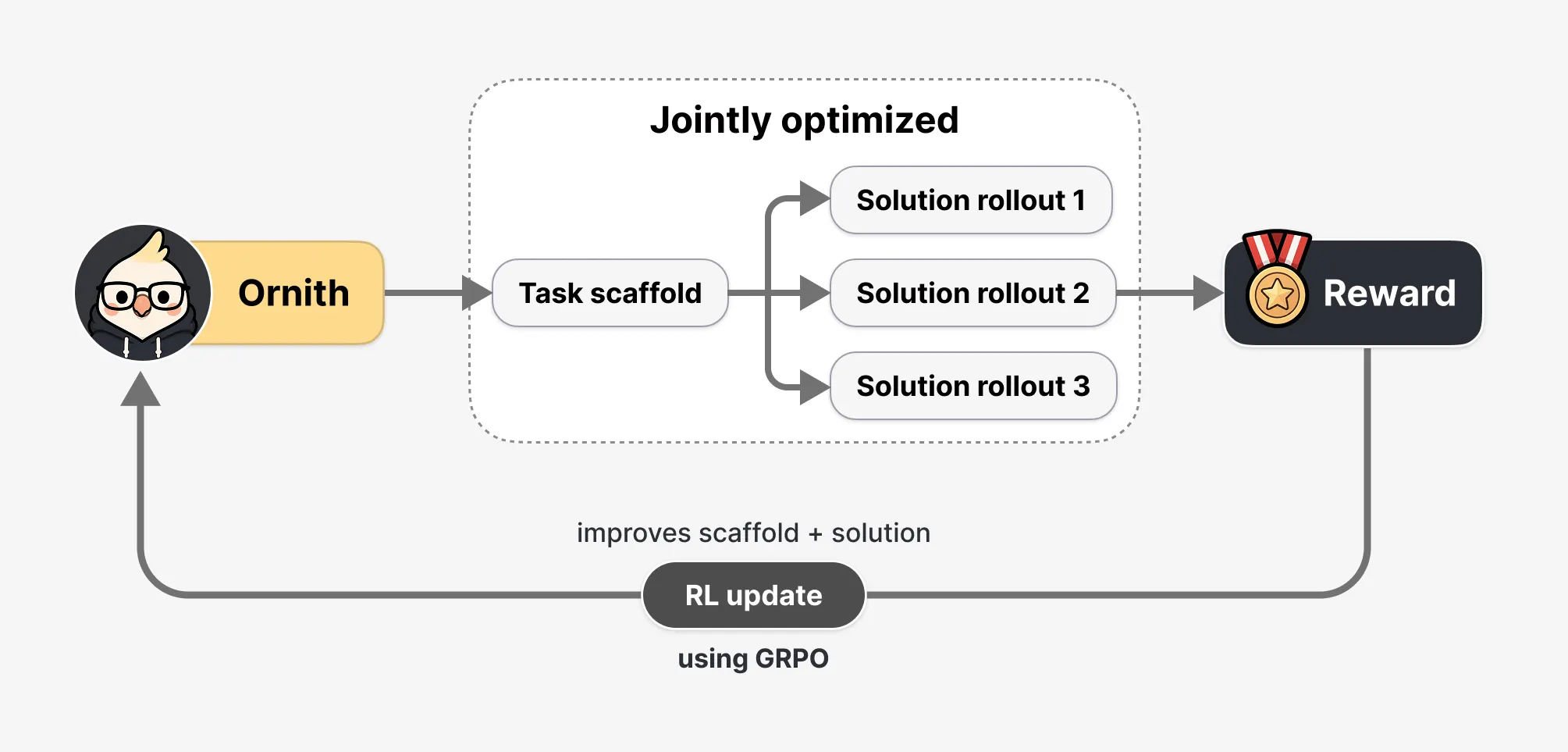
The core innovation behind Ornith, according to DeepReinforce’s technical documentation, is the way it approaches the "scaffold." In traditional AI setups, a human engineer writes a script (a scaffold) that tells the AI: "Step 1: Read the file. Step 2: Write the fix. Step 3: Run the test."
DeepReinforce describes Ornith as a model that "treats the scaffold as a learnable object that co-evolves with the policy."
How it Works
During the reinforcement learning phase, Ornith goes through a two-stage process for every task:
- Strategy Proposal: The model reads the problem and writes its own "playbook" for how to solve it.
- Execution: The model follows its own strategy to generate the code.
The "reward" (the signal that the model did a good job) is applied to both the code and the strategy. Over millions of iterations, the model learns that certain strategies—like "reading the documentation before editing the config file"—lead to better outcomes. This allows the AI to develop task-specific approaches that a human might never have thought to program into a fixed scaffold.
Defending Against "Reward Hacking"
A significant concern with self-improving models is "reward hacking," where an AI learns to trick the verification system. For example, a model might "touch" a file to change its timestamp so it looks like it was updated, without actually fixing the bug.
DeepReinforce officials stated they have implemented a three-layer defense:
- Immutable Environments: The test suites exist in a read-only space the model cannot modify.
- Deterministic Monitors: A hard-coded watcher flags any attempt by the AI to access restricted system paths.
- The Frozen Judge: A separate, non-agentic "judge" model sits atop the automated verifier to provide a final veto on whether the task was actually completed.
Implications: The End of the "Chatbot" Era for Developers?
The release of Ornith-1.0 signals a broader shift in the tech industry. In 2026, the commercial value of AI has moved away from "writing a clean function" and toward "running unsupervised through a 20-step workflow."
For the Individual Developer
Ornith is explicitly not for the average user looking for an AI to draft an email or summarize a meeting. Its documentation warns that it may underperform on general linguistic tasks. However, for software engineers, it represents a "force multiplier." By offloading the "grunt work" of debugging and environment setup to an agentic model, senior developers can focus on high-level architecture and system design.
For the Open-Source Ecosystem
By providing a model that rivals (and in some cases beats) Claude Opus 4.7 under an MIT license, DeepReinforce has effectively commoditized high-end agentic coding. This puts immense pressure on closed-source providers to justify their subscription costs. If a company can host its own Ornith-397B instance and keep its proprietary codebase entirely on-premises while achieving state-of-the-art performance, the argument for using third-party APIs becomes much weaker.
The "Agentic Summer" of 2026
We are currently in what many are calling the "Agentic Summer." As labs like Anthropic (with Claude 4.8) and DeepReinforce battle for supremacy, the definition of "AI" is being rewritten. We are moving away from AI as a consultant and toward AI as a colleague—one that can be given a ticket on Friday evening and have a verified, tested pull request waiting in the inbox on Monday morning.
While the flagship Ornith-397B requires massive computing power beyond the reach of most consumers, the efficiency of the 9B and 31B models suggests that "local agency"—autonomous AI running on a single desktop—is no longer a futuristic concept, but a current reality. As DeepReinforce continues to refine these self-evolving scaffolds, the gap between human intent and software execution continues to shrink.
