
Date: June 30, 2026
Funding: Supported by Paradigm
In the rapidly evolving landscape of artificial intelligence, the Transformer architecture has reigned supreme, largely due to its unparalleled ability to perform associative recall (AR). By allowing every token in a sequence direct, simultaneous access to all preceding tokens through the attention mechanism, Transformers have set the gold standard for long-range dependency modeling. However, this power comes at a steep price: quadratic computational complexity. As sequences grow longer, the memory and processing requirements of Transformers skyrocket, creating a significant bottleneck for applications that demand high-efficiency, long-horizon processing, such as advanced Reinforcement Learning (RL) frameworks like Dreamer.
For researchers working in these specialized domains, the quest to revive Recurrent Neural Networks (RNNs) without sacrificing the associative recall capabilities of Transformers has become a primary objective. A new breakthrough, utilizing orthogonalization techniques, suggests that we may finally be closing the gap between the efficiency of RNNs and the recall prowess of Transformers.
The Associative Recall Dilemma
At the core of the problem lies the difference in how Transformers and RNNs handle information. Transformers treat the context window as a flat, accessible space. RNNs, by contrast, attempt to compress the entire history of a sequence into a fixed-size hidden state. While this makes them computationally cheaper, it historically leads to "forgetting" or the inability to retrieve specific historical associations—the very definition of associative recall.
The current state-of-the-art for recurrent associative memory is the mLSTM (multiplicative LSTM), which introduces a matrix memory component to store information. While mLSTMs have shown marked improvements over standard LSTMs in benchmarks like the Multi-Query Associative Recall (MQAR), pure recall is often a sterile metric. In real-world environments, inputs are rarely clean; they are noisy, interleaved, and complex. To truly test an RNN, researchers must look toward Noisy Associative Recall (NAR), a proxy task that requires models to retrieve information while filtering out irrelevant "distractor" tokens.
Chronology of a Technical Intervention
The development of the orthogonalized mLSTM was not a stroke of luck, but an iterative process of cross-pollinating ideas from optimization theory and sequence modeling.
The Influence of Muon
The project began by examining Muon, a novel optimizer that has gained significant traction for its ability to stabilize deep learning training. Muon functions by orthogonalizing the momentum buffers of a model, essentially acting as an equalizer for represented directions. By preventing a small number of "strong" features from dominating the gradient update, Muon ensures that weaker, more nuanced signals are not "crowded out" during the learning process. Recent studies have demonstrated that Muon outperforms standard optimizers like Adam in tail-end associative memory learning, proving that the geometry of the weight space is just as important as the architecture itself.
The Hypothesis
The researchers hypothesized that if Muon’s orthogonalization could improve associative memory in standard architectures, a similar principle could be applied to the mLSTM’s internal memory matrix. By forcing the readouts of the mLSTM to be orthogonal, they sought to prevent memory interference, where multiple stored associations bleed into one another and degrade retrieval accuracy.
The Implementation
The team designed an experiment to test this by integrating a Newton-Schulz iteration process into the mLSTM readout.
- Normalization: The memory matrix is normalized via the Frobenius norm.
- Newton-Schulz Iteration: The matrix undergoes five iterations of the Newton-Schulz algorithm to reach an orthogonal state.
- Selective Application: Crucially, the team discovered that writing the orthogonalized matrix back into the model’s weights actually degraded performance. Therefore, they implemented the process solely at the readout stage, allowing gradients to flow through the process during training without altering the core memory storage.
Supporting Data: Breaking the Performance Ceiling
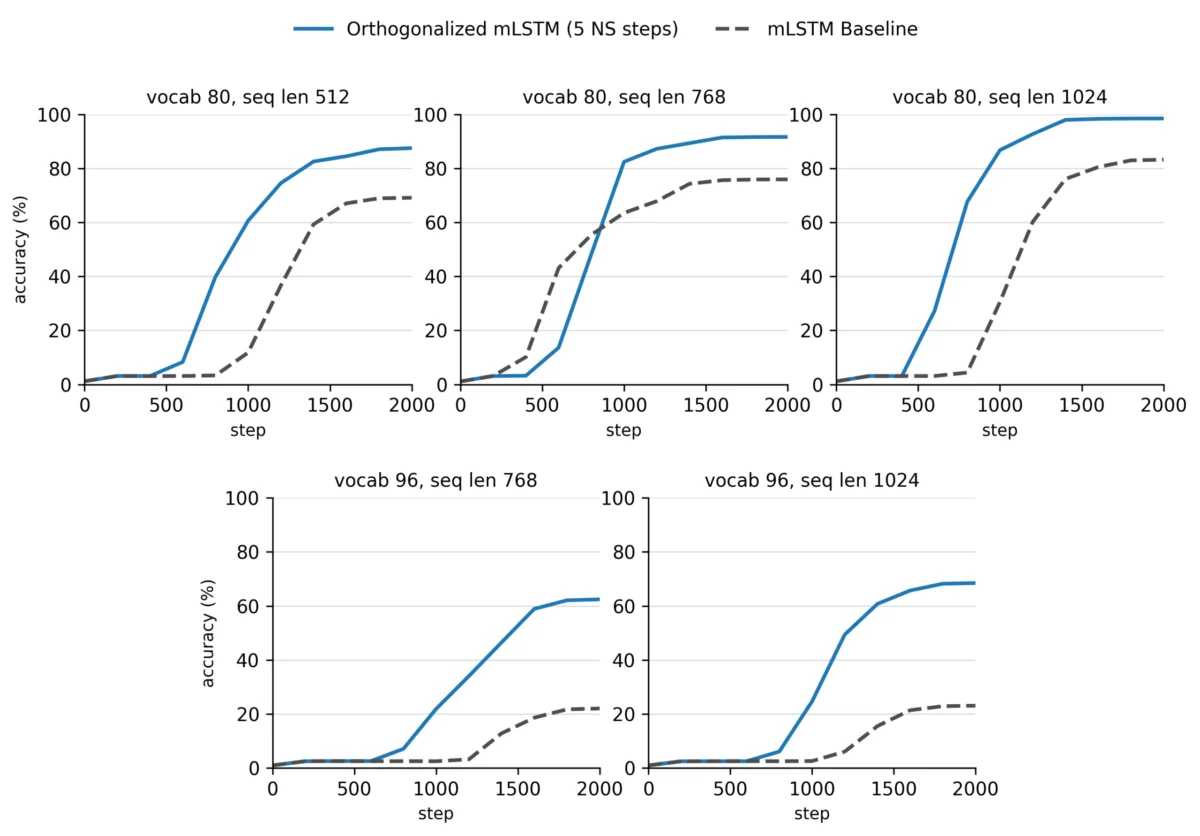
To validate this approach, the team utilized the MAD (Memory and Associative Data) noisy AR task suite. In this test, a model is provided with a sequence of key-value pairs interleaved with distractor tokens. A successful model must correctly predict a value based on a key seen much earlier in the sequence, while ignoring the noise.

Experimental Setup
- Dataset: MAD noisy-recall with a
frac_noisesetting of 0.8. - Training: AdamW optimizer with a batch size of 64 and a 2k-step duration.
- Comparison: Baseline mLSTM vs. Orthogonalized mLSTM across varying vocabularies (80–96) and sequence lengths (512–1024).
Quantitative Results
The results, captured in the team’s findings, were statistically significant. In the "vocab 80, length 1024" regime, the orthogonalized model achieved a staggering 98.5% accuracy, compared to 83.3% for the baseline. The performance gap widened even further as the task difficulty increased. In the "vocab 96, length 1024" regime, the baseline model essentially collapsed, solving only 4 out of 24 seeds. In contrast, the orthogonalized model maintained reliability across 16 seeds, effectively moving from near-failure to a robust, viable solution.
Official Perspective and Technical Implications
The researchers involved—supported by Paradigm—are careful to frame these findings as a "small intervention" with "large-scale implications." The primary takeaway is that the architecture of a recurrent network is only half the battle; the geometry of how that network retrieves information is equally vital.
Why Orthogonalization Works
The prevailing theory is that in a high-dimensional memory matrix, vectors can become "entangled" or collapse toward a few dominant axes. By enforcing orthogonality, the model is forced to distribute its representations across the full capacity of the memory matrix. This "equalization" ensures that even obscure associations—the "tail-end" memories—remain distinct and accessible when the model is queried.
The Trade-offs
While the gains in accuracy are undeniable, there is a cost. The Newton-Schulz iterations require additional FLOPs (floating-point operations) and increase the wall-clock time required for each training step. For real-time applications, this is a trade-off that must be carefully managed. However, for applications where accuracy and long-horizon reliability are paramount, the additional compute cost is arguably a small price to pay for the increased model stability.
Implications for the Future of AI
While these experiments were conducted on a synthetic, small-scale regime, the implications for the future of deep learning are profound.
Moving Beyond Transformers?
The success of this approach suggests that the "Transformer hegemony" may not be as inevitable as it once seemed. If RNNs can be augmented to achieve high-fidelity associative recall, they offer a pathway to linear-time inference. This would revolutionize mobile AI, edge computing, and long-horizon RL—fields where the memory footprint of current Transformers is often prohibitive.
Future Research Directions
The research team has open-sourced their code, inviting the broader community to test these methods on larger-scale, real-world datasets. Several critical questions remain:
- Generalization: Will these gains hold in large-scale language models (LLMs) or when dealing with unstructured natural language?
- Optimization: Can the Newton-Schulz iterations be optimized or approximated further to reduce the computational overhead?
- Integration: Can this orthogonalization technique be combined with other state-of-the-art RNN improvements, such as State Space Models (SSMs)?
The work represents a critical shift in focus: from building larger, more expensive attention mechanisms toward a more nuanced understanding of how we can force efficient recurrent architectures to "remember" better. As we look toward the next generation of AI, it is increasingly clear that the path to intelligence may not just be about how much we process, but how effectively we structure the memory we hold.
For those interested in the technical implementation and raw data, the researchers have made their full codebase and documentation available on GitHub.
