
In the rapidly evolving landscape of Large Language Models (LLMs), the challenge has shifted from simply generating text to performing complex, multi-file software engineering tasks. As AI-integrated development environments (IDEs) become the standard for modern coding, the industry requires a rigorous yardstick to measure how well these agents navigate real-world, ambiguous, and multi-file codebases. Enter CursorBench 3.1, the latest iteration of a performance evaluation framework designed to separate high-performing coding agents from the rest of the pack.
The release of the 3.1 results provides more than just a leaderboard; it offers a granular view of the trade-offs between computational cost, model latency, and reasoning capability. By evaluating agents on actual, anonymized sessions from the Cursor IDE, this benchmark moves beyond synthetic tests, grounding its findings in the gritty, unpredictable reality of software development.
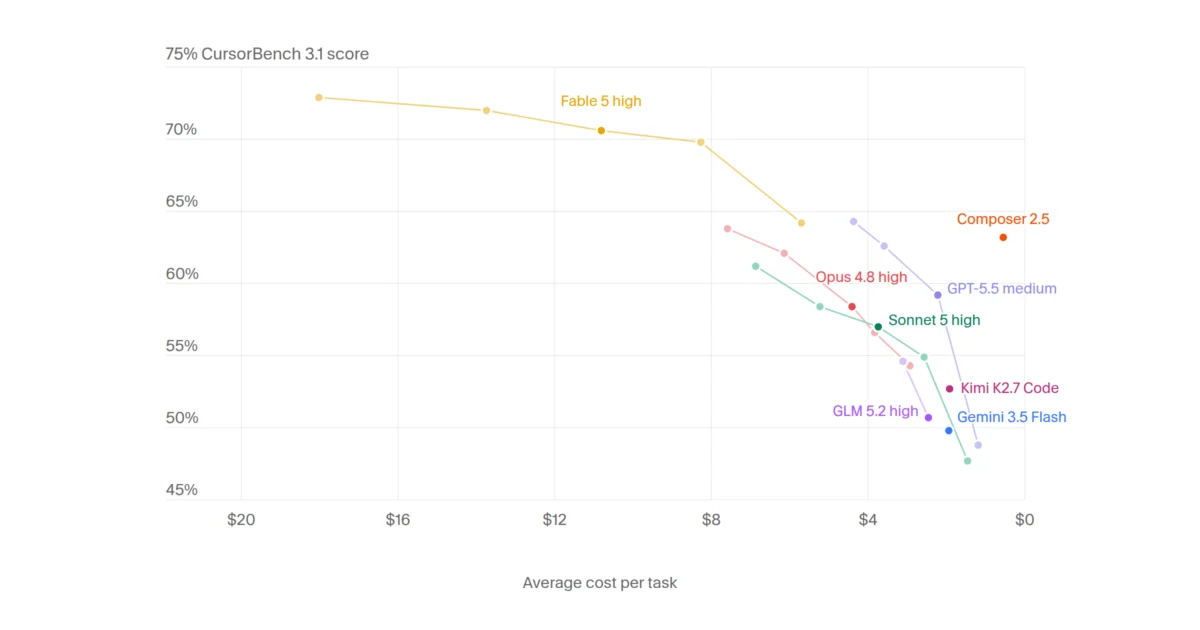
Main Facts: The State of the Leaderboard
The CursorBench 3.1 results reveal a landscape dominated by top-tier models that balance accuracy with economic efficiency. The current benchmark leader is Fable 5 Max, which secured a 72.9% score, setting the standard for complex problem-solving. However, the data highlights that performance often comes with a steep price tag, with Fable 5 Max averaging $18.02 per task.
What becomes immediately clear when analyzing the data is that "heavier" models do not always equate to a linear increase in quality. While Fable 5 dominates the top four spots, the efficiency-focused Composer 2.5 proves to be a standout performer. Scoring 63.2% while costing a mere $0.55 per task, Composer 2.5 demonstrates that for many workflows, the marginal gains provided by larger, more expensive models might not justify the significant spike in operational expenditure.
Key takeaways from the current rankings include:
- The Fable 5 Dominance: Across "Max," "Extra High," "High," and "Medium" configurations, Fable 5 consistently outperforms its competitors, maintaining a score floor of nearly 70% even in its medium tier.
- The Efficiency Gap: There is a stark divide between models optimized for high-throughput, low-cost operations (like Composer and Gemini 3.5 Flash) and those designed for exhaustive reasoning (like Fable 5 or Opus 4.8).
- Diminishing Returns: The data suggests a "ceiling" in current model architecture; increasing spending beyond $15 per task yields increasingly incremental improvements, suggesting that further gains may require architectural breakthroughs rather than simply scaling input/output tokens.
Chronology: The Evolution of CursorBench
The development of CursorBench has been a iterative process, reflecting the accelerated pace of AI research.
From 3.0 to 3.1
CursorBench 3.0 laid the groundwork by establishing the methodology of using real, user-provided sessions to grade agent performance. However, the jump to 3.1 was necessitated by the sudden influx of new, more capable models and a desire to refine the cost-to-performance metrics. The 3.1 update introduced a more refined set of test cases, specifically focusing on "ambiguity management"—the ability of an agent to ask clarifying questions or make safe assumptions when faced with incomplete information across multiple files.
The Rise of Multi-File Reasoning
Early iterations of coding benchmarks often focused on single-function generation. The shift in CursorBench reflects the industry’s pivot toward agentic workflows. As models gained the ability to "see" entire repositories, the criteria for success shifted from "Does this code run?" to "Does this code maintain consistency across a complex, multi-file dependency graph?" The 3.1 results confirm that this is where modern models still struggle, as evidenced by the variance in scores across the various model tiers.
Supporting Data: Understanding the Cost-Utility Curve
The data provided by the CursorBench 3.1 chart is a scatter plot of model performance against average cost per task. This visualization is essential for developers and businesses attempting to integrate AI into their CI/CD pipelines.
The Cost-Quality Correlation
When plotting the performance of models like GPT-5.5 and Sonnet 5, a clear trend emerges: the "High" and "Extra High" configurations of these models typically occupy the mid-range of both cost and performance. The data suggests that if a task is routine, the "Medium" or "Low" tiers are statistically sufficient. However, for architectural changes or complex debugging—where the cost of a hallucination is high—the "Max" tiers of models like Fable 5 provide the necessary insurance, albeit at a premium.
Statistical Significance
It is vital to note, as the developers of CursorBench emphasize, that results are subject to variance. Small differences—for instance, the 0.9% gap between Fable 5 Extra High and Fable 5 High—may not represent a fundamental difference in intelligence, but rather the specific nature of the test suite. Developers should view these rankings as a guide to model "tiers" rather than an absolute, immutable hierarchy of intelligence.
Official Perspectives and Model Limitations
The creators of CursorBench have been transparent about the limitations of their testing environment. The primary constraint is the "ambiguity" factor. Unlike a standardized test, a real-world coding task is rarely well-defined. An agent that performs exceptionally well in a vacuum might fail in the field because it lacks the context of a specific company’s coding style or internal documentation.
Furthermore, the pricing model used in the report is based on current per-million-token market rates. These are subject to change as cloud providers adjust their infrastructure costs. The benchmark is, by definition, a snapshot in time. As models like the Opus 4.x series or GLM 5.2 receive updates, their positions on this chart are likely to shift, potentially disrupting the current dominance of Fable 5.
Industry feedback has largely praised the shift toward "real-world" tasks. In forums and engineering circles, the consensus is that benchmarks like HumanEval are becoming obsolete, as models have effectively "memorized" them. By using proprietary, anonymized user data, CursorBench offers a "black box" test that is much harder for model developers to game.
Implications: The Future of Agentic Development
The data from CursorBench 3.1 has profound implications for the future of software engineering.
1. The Death of the "One Size Fits All" Model
We are moving toward a future where developers will use a "model orchestrator" that dynamically routes tasks to different models based on their complexity and cost. A simple bug fix might be routed to a low-cost, high-speed model like Composer 2, while a major refactoring project is handled by Fable 5 Max. This tiered approach will be essential for keeping AI-assisted development economically viable at scale.
2. The Focus on Latency
While CursorBench 3.1 focuses on cost and accuracy, the elephant in the room remains latency. The "Max" versions of these models often require significant time to process multi-file contexts. Future benchmarks will likely need to incorporate "time-to-first-token" or "total task duration" as a primary variable, as a high-performing agent that takes ten minutes to process a file is often less useful than a slightly less accurate agent that finishes in thirty seconds.
3. The Democratization of Complex Engineering
The success of models like Composer 2.5, which provides a high level of reasoning for less than a dollar per task, suggests that the barrier to entry for building complex software is falling. As these tools become cheaper and more accurate, the role of the human engineer will continue to shift from "writer of code" to "architect and reviewer of agent-generated systems."
Final Thoughts
CursorBench 3.1 is more than a list of winners and losers; it is a roadmap for the future of AI in the workplace. It challenges us to think critically about the value of an AI’s output and forces a conversation about the economics of intelligence. As we look toward the 4.0 release, the industry will undoubtedly continue to refine these metrics, pushing the boundaries of what is possible when human intent meets machine-speed execution. For now, the takeaway is clear: the agents are getting better, they are getting cheaper, and they are here to stay.
